Hanxue Liang1, Jiawei Ren2, Ashkan Mirzaei4, Antonio Torralba5, Ziwei Liu2, Igor Gilitschenski3, Sanja Fidler3, Cengiz Oztireli1, Huan Ling3, Zan Gojcic2, Jiahui Huang2
1University of Cambridge, 2NVIDIA, 3Nanyang Technological University, 4University of Toronto, 5MIT
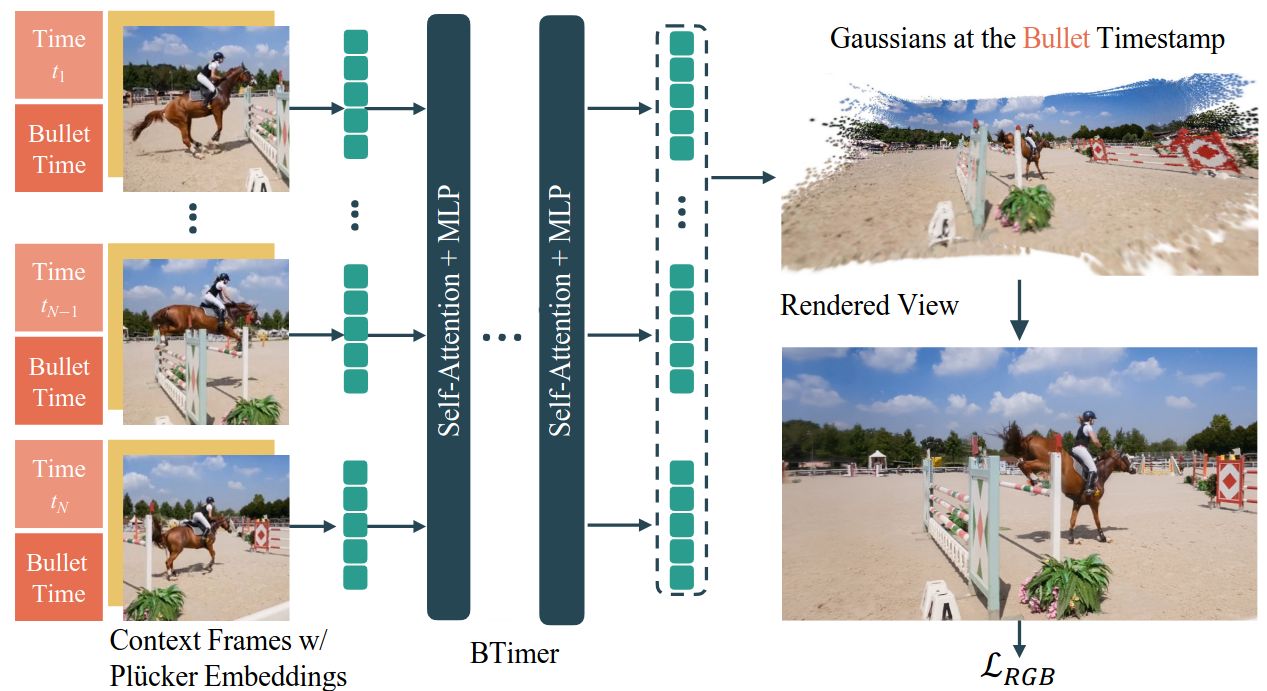
Recent advancements in static feed-forward scene reconstruction have demonstrated significant progress in high-quality novel view synthesis. However, these models often struggle with generalizability across diverse environments and fail to effectively handle dynamic content. We present BTimer (short for Bullet Timer), the first motion-aware feed-forward model for real-time reconstruction and novel view synthesis of dynamic scenes. Our approach reconstructs the full scene in a 3D Gaussian Splatting representation at a given target (‘bullet’) timestamp by aggregating information from all the context frames. Such a formulation allows BTimer to gain scalability and generalization by leveraging both static and dynamic scene datasets. Given a casual monocular dynamic video, BTimer reconstructs a bullet-time scene within 150ms while reaching state-of-the-art performance on both static and dynamic scene datasets, even compared with optimization-based approaches.
Links:
Paper