Endri Dibra1, Thomas Wolf1, Cengiz Öztireli1, Markus Gross1
1Department of Computer Science, ETH Zürich
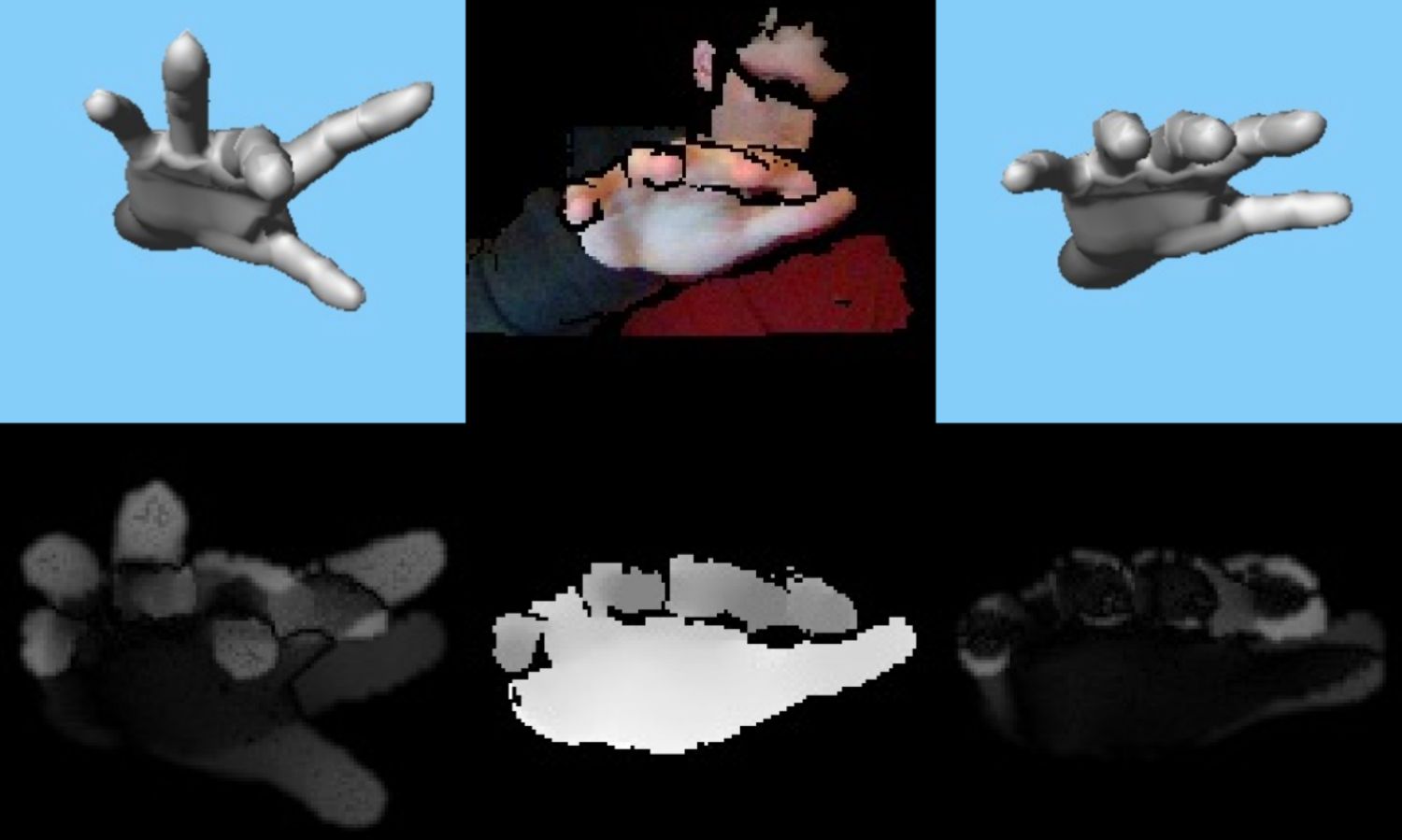
We attach a video, consisting of three main parts, which show some qualitative results on the optimization procedure explained in the paper, as well as additional qualitative results obtained from a real subject. In the first two parts, Pose Optimization and Shape Optimization, we adapt the base model and hand shape to a single image until convergence. This serves to visualize the Sec 4.3 from the paper and gives insight on how the pose predictions get updated during learning. In the next part, Comparisons, we show two videos, comparing the base model to the adapted model trained on our dataset (with 50K unlabelled images). This refers to Sec 4.4 in the paper. The first video shows a validation sequence of 300 frames with various hand poses. The second video shows a live prediction using the Intel RealSense SR300 camera. Note that not only the pose prediction quality is enhanced, but also jitter is removed significantly.
Links:
PDF